Ziel
Es soll ein Entscheidungsbaum erzeugt werden, der aus Bewerbungen für das Informatikstudium diejenigen herausfiltert, die das Studium voraussichtlich erfolgreich absolvieren.
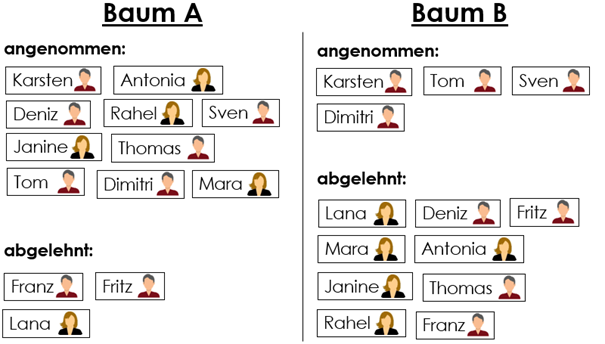
Als Trainingsdaten werden Daten ehemaliger Studierender genutzt. Grüne Karten stehen für erfolgreiche Ehemalige, die man wieder zulassen würde, rote Karten für nicht erfolgreiche, die man besser abgelehnt hätte.
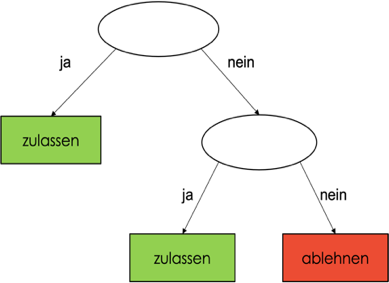
Daten
Folgende binäre Merkmale sind erhoben worden:
- Abiturnote besser als 2.0?
- Informatik-LK?
- Geschlecht männlich?
Folgende Beispieldaten stehen zur Verfügung:


Download der Beispieldaten in Kartenform (für zwei Bäume A und B)
Download der Beispieldaten im CSV-Format (für zwei Bäume A und B)
Baum erstellen
In folgendem Video wird erläutert, wie ein Entscheidungsbaum für eine Kaufentscheidung erstellt werden kann.
Mit Hilfe dieser Informationen soll anschließen der Entscheidungsbaum für die Studienentscheidung erstellt werden.
Algorithmus in Pseudocode
Falls alle Personen der Liste zugelassen werden,
schreibe "zugelassen" in die Wurzel des aktuellen Baums und beende.
Falls alle Personen der Liste abgelehnt werden,
schreibe "ablehnen" in die Wurzel des aktuellen Baums und beende.
Sonst
Schreibe das erste Merkmal der Liste in die Wurzel/Knoten und entferne es aus der Liste.
Teile die Liste mit Personen so in zwei Listen, dass alle Personen in der ersten Liste das Merkmal in der aktuellen Wurzel erfüllen und alle in der zweiten Liste nicht.
Wende das Verfahren auf den linken Teilbaum, die erste Liste und die Liste mit Merkmalen an.
Wende das Verfahren auf den rechten Teilbaum, die zweite Liste und die Liste mit Merkmalen an.
Lösung – trainierte Bäume A und B

Baum A (links: ja, rechts: nein):
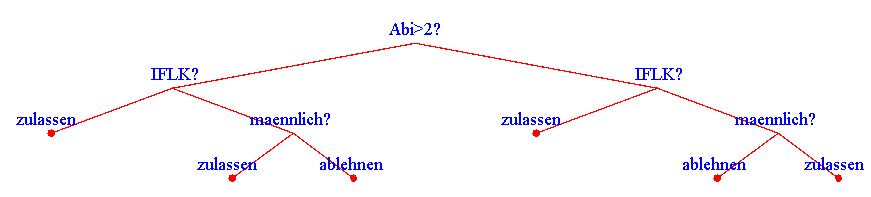
Baum B (links: ja, rechts: nein):
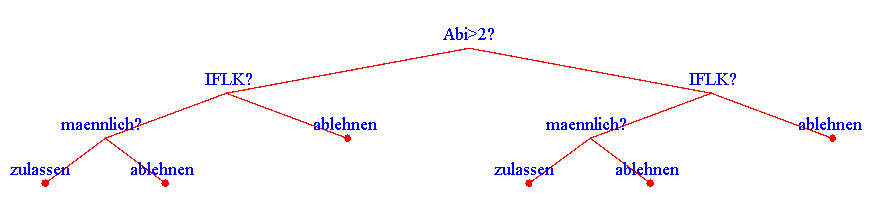
Baum auf neue Daten anwenden
Folgende neue Daten werden nun auf die Bäume angewendet:
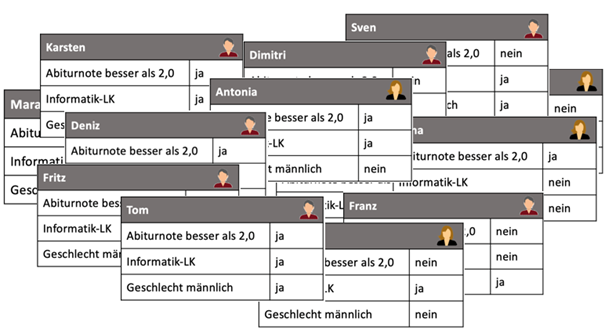
Auswertung, Qualität
Folgendes Ergebnis bringen die beiden Bäume mit den neuen Daten:
Folgende Erkenntnisse erlangt man:
- Hat man unterschiedliche Trainingsdaten, sehen die Bäume unterschiedlich aus und damit auch deren Entscheidungen.
- Baum B diskriminiert systematisch Frauen. Wir haben hier also einen Bias vorliegen.
- Es darf bezweifelt werden, dass eine KI über Studienzulassungen entscheiden sollte.
- Die Trainingsdaten sind also sehr entscheidend für die spätere Güte des Entscheidungsbaumes.
Bemerkung
Die Beispieldaten sind so gewählt, dass es nicht passieren kann, dass Datensätze widersprüchlich sind, indem zwei Daten dieselben Merkmalsausprägungen haben, aber zu unterschiedlichen Entscheidungen führen.
Ebenso wurde nicht diskutiert, mit welchem Merkmal man beginnen sollte und welchen Unterschied das macht.
Genauso wenig mussten die Schwellwerte für die Merkmale selbst ermittelt werden.
All dies lässt sich aber natürlich auch an diesem Beispiel umsetzen.
Umsetzung in Java-Programm
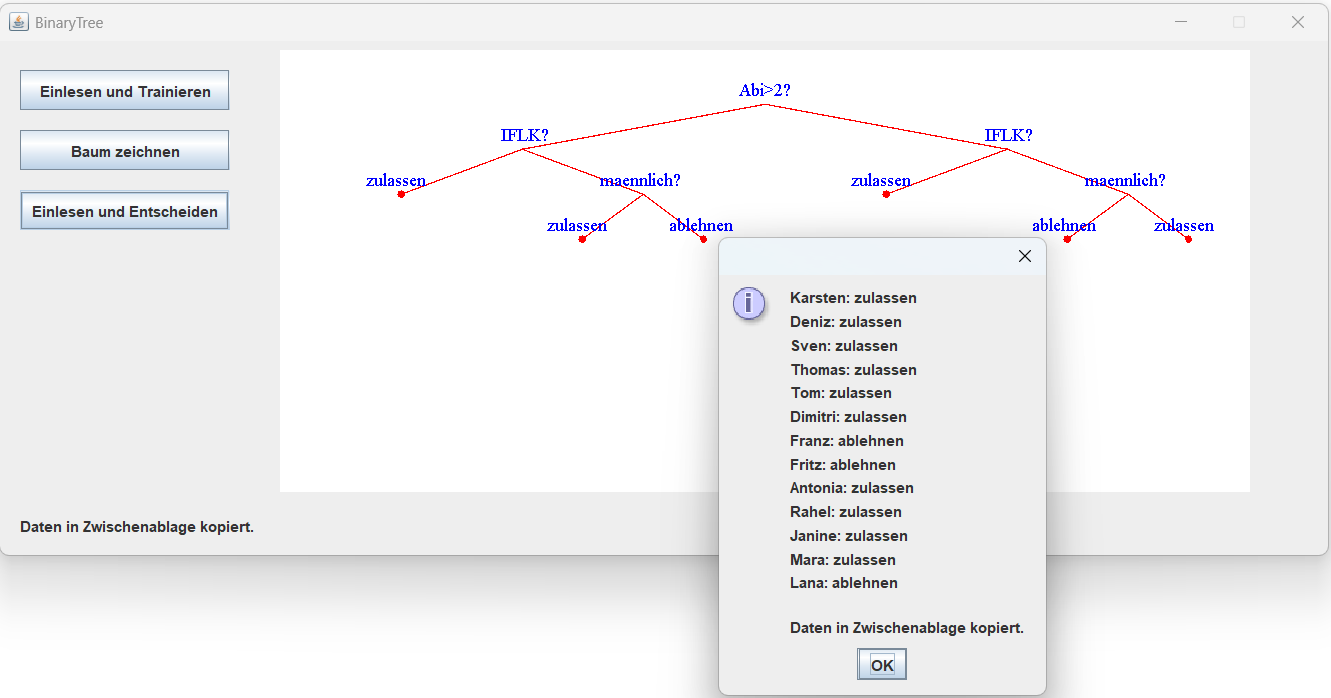
In folgendem Programm ist die Erzeugung und Anwendung des Entscheidungsbaumes umgesetzt. Für dieses Programm gelten allerdings auch die Unter "Bemerkung" gemachten Einschränkungen.
Java-Quelltext
Zum Starten der Anwendung die Datei BaumGui.java compilieren und ausführen. Dann zunächst die CSV-Datei mit den Trainingsdaten einlesen lassen, den Baum zeichnen und anschließend für die neuen Daten aus der entsprechenden CSV-Datei die Entscheidung zur Studienzulassung durch den Baum treffen lassen.