Ziel
Daten sollen so in Gruppen angeordnet werden, so dass ähnliche Daten in einer Gruppe sind.
Algorithmus
-
Schritt: Bestimme die Anzahl der Gruppen (K)
Angenommen, du willst zwei Gruppen bilden. Dann setzt du K=2, also zwei Cluster. -
Schritt: Wähle zufällige Startpunkte
Der Algorithmus wählt zwei zufällige Datensätze als erste „Mittelpunkte“ der beiden Gruppen. Diese Mittelpunkte nennt man Zentroiden. -
Schritt: Weise jedem Datensatz eine Gruppe zu
Jeder Datensatz wird nun der Gruppe zugewiesen, deren Mittelpunkt ihm am nächsten ist. -
Schritt: Berechne neue Mittelpunkte
Nachdem alle Datensätze einer Gruppe zugeordnet wurden, berechnet der Algorithmus den neuen Mittelpunkt jeder Gruppe. Dazu nimmt er den Durchschnitt aller Werte der Datensätze in einer Gruppe. -
Schritt: Wiederhole die Schritte 3 und 4
Die Datensätze werden erneut der nächsten Gruppe zugeordnet, basierend auf den neuen Mittelpunkten. Das wiederholt sich, bis sich die Gruppen nicht mehr verändern.
Beispiel 1: Kundengruppen im Supermarkt
Angenommen, ein Supermarkt möchte seine Kunden in Gruppen einteilen, um gezielte Werbung zu machen. Der Supermarkt hat Daten darüber, wie oft Kunden einkaufen und wie viel Geld sie im Monat ausgeben.
| Kunde | Einkäufe pro Monat | Monatsausgaben (€) |
|---|---|---|
| A | 2 | 50 |
| B | 10 | 400 |
| C | 4 | 120 |
| D | 8 | 350 |
| E | 4 | 180 |
| F | 7 | 480 |
Java-Implementierung
Download der Java-Quelltexte
Auswertung
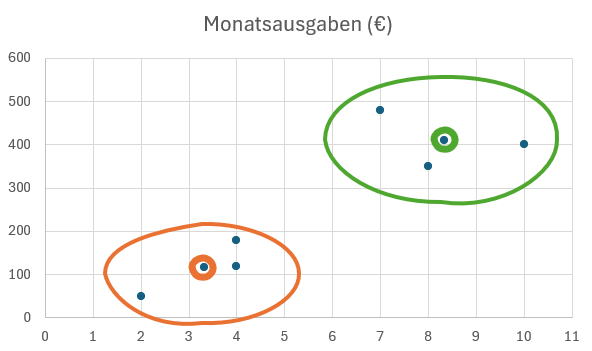
Kunden-Zuordnung zu Clustern:
Kunde 1 (Einkäufe: 2, Ausgaben: 50) -> Cluster 1
Kunde 2 (Einkäufe: 10, Ausgaben: 400) -> Cluster 2
Kunde 3 (Einkäufe: 4, Ausgaben: 120) -> Cluster 1
Kunde 4 (Einkäufe: 8, Ausgaben: 350) -> Cluster 2
Kunde 5 (Einkäufe: 4, Ausgaben: 180) -> Cluster 1
Kunde 6 (Einkäufe: 7, Ausgaben: 480) -> Cluster 2
Finale Cluster-Zentroiden:
Cluster 1: (Einkäufe: 3,33, Ausgaben: 116,67)
Cluster 2: (Einkäufe: 8,33, Ausgaben: 410,00)
Beispiel 2: Goldsucher mit Greenfoot
