Ziel
Es soll ein KI-System entwickelt werden, welches kurze Sätze auf ihre Stimmung hin analysiert.
Zum Beispiel soll der Satz „Der Film war fantastisch und mitreißend.“ als positiv bewertet werden, „Ich hasse es, wie der Regen heute den Tag ruiniert.“ als negativ und „Das Buch war durchschnittlich, nicht besonders spannend.“ als neutral.
Das KI-System könnte später in einem Chat-Programm eingesetzt werden, um die Stimmung der Schreibenden einschätzen und entsprechend reagieren zu können.
Als KI-Modell wählen wir ein Neuronales Netz.
Ablauf
Zur Entwicklung des KI-Systems durchlaufen wir folgende Schritte:
- Daten beschaffen bzw. auswählen
- Daten in Trainings- und Testdaten teilen
- Daten aufbereiten für ein KI-Modell
- Implementation eines KI-Systems zur Nutzung eines bestehenden KI-Modells (z.B. NN oder Entscheidungsbaum oder …) unter Nutzung der Trainings- und Testdaten
- Training des KI-Modells
- Test des KI-Systems
- Qualität des KI-Systems bestimmen (Wie viele von den Testdaten werden richtig klassifiziert?, Bias, Underfitting, Overfitting, Präzision, Spezifität)
1 - Daten beschaffen bzw. auswählen und aufbereiten für ein KI-Modell
Wir lassen uns von einer generativen KI 100 kurze Sätze erstellen und bewerten deren Stimmung. Alternativ können wir uns die Texte auch selbst ausdenken.
Die Erstellung der 100 verschiedenen kurzen Sätze und deren Bewertung ist auch für eine generative KI eine herausfordernde Aufgabe, bei der Fehler passieren können. Dies ist ein Beispiel, wozu „Klickarbeiter“ benötigt werden (z.B. für die korrekte Bewertung der generierten Sätze).
Im Folgenden ein Ausschnitt dieser Daten.
| ID | Text | Sentiment |
|---|---|---|
| 1 | Der Film war fantastisch und mitreißend. | positiv |
| 2 | Ich hasse es, wie der Regen heute den Tag ruiniert. | negativ |
| 3 | Das Buch war durchschnittlich, nicht besonders spannend. | neutral |
| 4 | Das Konzert war ein unvergessliches Erlebnis. | positiv |
| 5 | Das Essen war kalt und geschmacklos. | negativ |
| 6 | Die neue Schülerin hat sich schnell integriert. | positiv |
| 7 | Die Prüfung war extrem schwer und frustrierend. | negativ |
| 8 | Das Wetter ist heute normal, nicht zu heiß und nicht zu kalt. | neutral |
| ... | ... | ... |
| 99 | Der Kunstunterricht inspirierte mich sehr. | positiv |
| 100 | Der Physikunterricht wirkte sehr trocken und öde. | negativ |
2 - Daten in Trainings- und Testdaten teilen
Sinnvoll ist eine Aufteilung im Verhältnis 80% zu 20%.
- Trainingsdaten: Die ersten 80 Datensätze.
- Testdaten: Die letzten 20 Datensätze.
Außerdem speichern wir beide Datensammlungen in jeweils einer CSV-Datei, welche hier heruntergeladen werden können:
Achtung: Die Daten sind KI-generiert und nicht auf Korrektheit überprüft worden.
Beispielhafter CSV-Inhalt:
ID,Text,Sentiment
1,"Der Film war fantastisch und mitreissend.","positiv"
2,"Ich hasse es, wie der Regen heute den Tag ruiniert.","negativ"
3,"Das Buch war durchschnittlich, nicht besonders spannend.","neutral"
...
Damit wir im Folgenden die Codierung nicht beachten müssen, haben wir alle folgenden Buchstaben entsprechend in der CSV-Datei ersetzt: ä=ae, ü=ue, ö=oe, ß=ss
3 - Daten aufbereiten für ein KI-Modell
Unser neuronales Netzwerk kann ausschließlich Zahlen verarbeiten. Daher müssen wir uns überlegen, wie wir Ein- und Ausgabe so gestalten, dass dafür Zahlen benutzt werden.
Wörterbuch erstellen
Die Idee ist, ein Wörterbuch zu erstellen. Wir nutzen dazu die Bag-of-Words-Methode („Beutel von Wörtern“). Dazu gehen wir unsere Trainingsdaten durch und sammeln die vorkommenden Wörter. Dabei darf jedes Wort nur genau einmal vorkommen. Diese Sammlung nennen wir unser „Wörterbuch“.
Dies setzen wir in einem Java-Programm um – wir nutzen beispielsweise eine Array-List, durchlaufen jedes Wort jedes Satzes und fügen es hinzu, wenn es noch nicht vorhanden ist.
So entsteht in unserem Beispiel ein Wörterbuch mit 232 Datensätzen:
- der
- film
- war
- fantastisch
- und
- mitreißend
- ich
- hasse
- es
- wie
- regen
- heute
- den
- tag
- ruiniert
- das
- buch
- durchschnittlich
- nicht
- besonders
- spannend
- …
- uninteressant
Beachte: Das Wörterbuch wird nur aus den Sätzen der Trainingsdaten erstellt.
Das ganze Wörterbuch kann hier heruntergeladen werden: woerterbuch.txt
Text in Zahlen umwandeln (Feature-Vektoren)
Für jeden Satz erstellen wir einen Zahlenvektor, der angibt, welche Wörter aus unserem Wörterbuch im Satz vorkommen. Steht ein Wort im Satz, schreiben wir an dessen Stelle eine 1, sonst eine 0. So wird der Text in eine Form gebracht, die der Computer versteht.
Das Wörterbuch hat 232 Einträge – der Vektor hat also 232 Stellen. Der Satz "Das Essen war kalt und geschmacklos." wird in Kleinbuchstaben in folgende Wörter umgewandelt:
- "das"
- "essen"
- "war"
- "kalt"
- "und"
- "geschmacklos"
In unserem Vokabular (mit 0-basierter Indizierung) entsprechen diese Wörter folgenden Positionen:
- "das" → Index 15
- "essen" → Index 25
- "war" → Index 2
- "kalt" → Index 26
- "und" → Index 4
- "geschmacklos" → Index 27
Daraus ergibt sich für den Satz "Das Essen war kalt und geschmacklos." folgender Vektor:
[0, 0, 1, 0, 1, 0, 0, 0, 0, 0, // Indizes 0-9
0, 0, 0, 0, 0, 1, 0, 0, 0, 0, // Indizes 10-19
0, 0, 0, 0, 0, 1, 1, 1, 0, 0, // Indizes 20-29
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // Indizes 30-39
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // Indizes 40-49
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // Indizes 50-59
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // Indizes 60-69
…
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // Indizes 190-199
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // Indizes 200-209
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // Indizes 210-219
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // Indizes 220-229
0, 0] // Indizes 230, 231
Sentiments in One-Hot-Vektoren umwandeln
Für jeden Satz muss die Stimmung (Sentiment) auch als Zahl codiert werden. Wir entscheiden uns hier für einen One-Hot-Vektor, der uns für jede Stimmung mit einem Wert von 0 oder 1 angibt, welche Stimmung vorliegt. Dabei gilt:
- positiv: [1, 0, 0]
- neutral: [0, 1, 0]
- negativ: [0, 0, 1]
Unser Neuronales Netz wird später für jeden Index einen Wert zwischen 0 und 1 zurückgeben. Für den höchsten dieser Werte wird die entsprechende Stimmung angenommen.
4 - Implementation eines KI-Systems zur Nutzung eines bestehenden KI-Modells unter Nutzung der Trainings- und Testdaten
Als KI-Modell wählen wir das von D. Garmann und O. Heidbüchel implementierte Neuronale Netz und legen zunächst die Eckdaten fest.
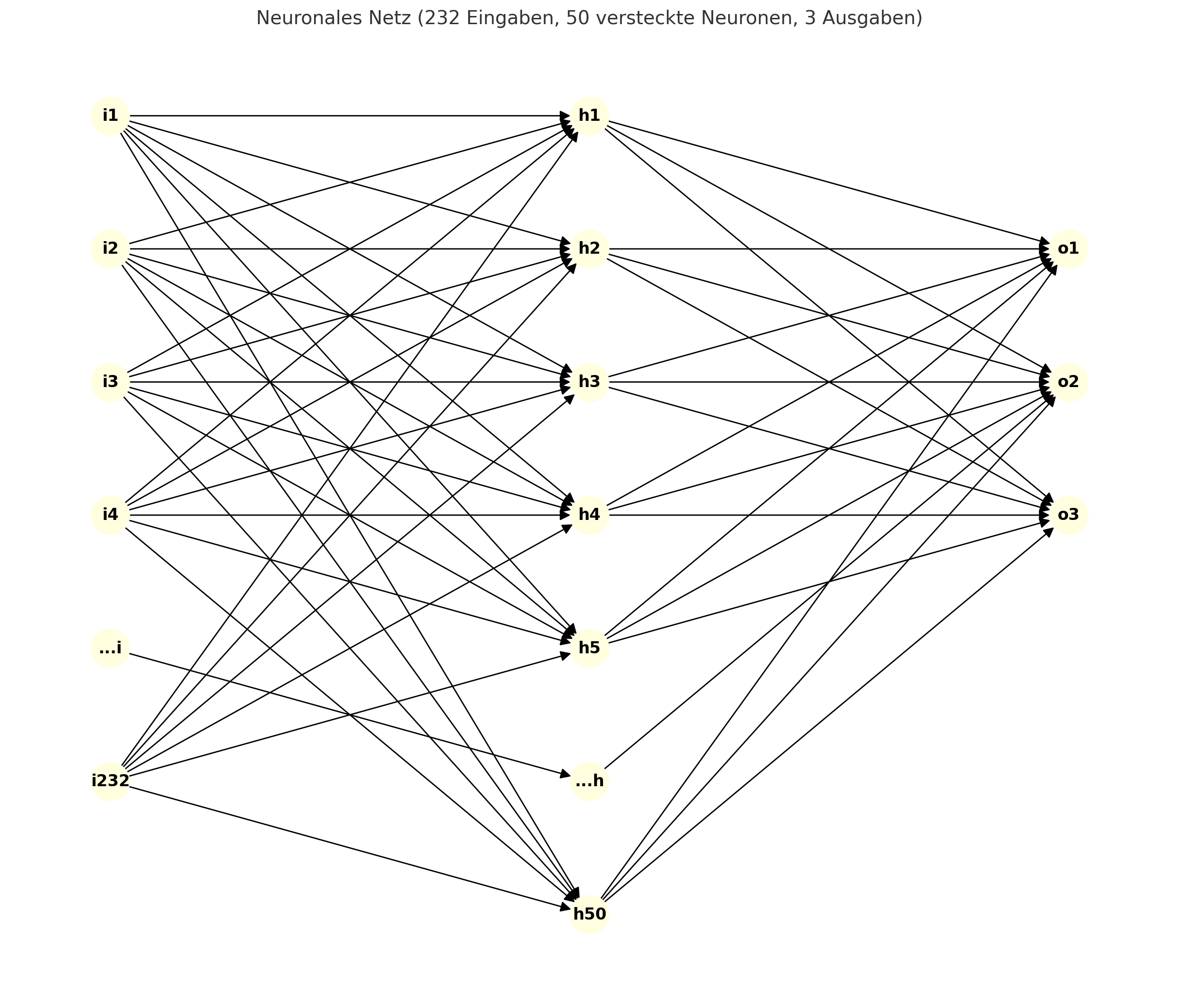
Definition des neuronalen Netzwerks
- Eingabeschicht: 232 Neuronen (entspricht der Größe unseres Wörterbuchs).
- Verdeckte Schicht: 50 Neuronen (zur Mustererkennung – hier können auch weitere Schichten ausprobiert werden).
- Ausgabeschicht: 3 Neuronen (entsprechend den drei möglichen Stimmungen: positiv, neutral, negativ).
- Aktivierungsfunktion: Sigmoidfunktion (unser KI-Modell bietet außerdem noch die tanh-Funktion an – für eine Klassifikation scheint Sigmoid besser geeignet).
- Lernrate: 0,1
- Trainingszyklen: 1000 (das komplette Trainingsset wird 1000-mal durchlaufen).
- Paketgröße: 5 (nach jeweils 5 Datensätzen werden die Gewichte neu angepasst).
Beispielhafter Java-Quellcode
Auszug aus der Klasse SentimentNetzCSV:
[...]
// Eingabeschicht: 232 Neuronen
int inputSize = vocab.size();
// Verdeckte Schicht: 50 Neuronen, Ausgabeschicht: 3 Neuronen
int[] neuronenProSchicht = {50, 3};
Aktivierungsfunktion af = new Sigmoid(); // Sigmoid-Aktivierungsfunktion verwenden
Netz netz = new Netz(inputSize, neuronenProSchicht, af); // Neuronales Netz erstellen
// Trainingsdaten vorbereiten
double[][] eingaben = new double[trainingExamples.size()][];
double[][] ausgaben = new double[trainingExamples.size()][];
for (int i = 0; i < trainingExamples.size(); i++) {
eingaben[i] = vocab.getFeatures(trainingExamples.get(i).getText());
ausgaben[i] = sentimentToOutput(trainingExamples.get(i).getSentiment());
}
//eingaben[i] ist der i-te Satz aus den Trainingsdaten. Jeder Satz besteht aus einen Vektor mit 232
//Einträgen (für jedes Eingabeneuron einen Wert 0 oder 1).
//ausgaben[i] ist das Gefühl zum i-ten Satz aus den Trainingsdaten. Jedes Gefühl besteht aus
//einem Vektor mit 3 Einträgen (postiv/neutral/negativ). Einer der Einträge ist 1, alle anderen 0.
// Trainingsparameter
double lernrate = 0.1;
int paketGroesse = 5;
int wiederholungen = 1000;
[...]
Ausgaben interpretieren
Unser Neuronales Netz gibt am Ende für jeden Datensatz einen Ergebnisvektor mit drei Einträgen zwischen 0 und 1 zurück, deren Summe 1 ist. Wir können diese Werte als Wahrscheinlichkeiten für die einzelnen Stimmungen interpretieren. Für den höchsten dieser Werte entscheiden wir uns als finale Stimmung.
Folgende Java-Methode setzt dies um:
public static String outputToSentiment(double[] output) {
int maxIndex = 0;
for (int i = 1; i < output.length; i++) {
if (output[i] > output[maxIndex]) {
maxIndex = i;
}
}
switch (maxIndex) {
case 0:
return "positiv";
case 1:
return "neutral";
case 2:
return "negativ";
default:
return "unbekannt";
}
}
5 - Training des KI-Modells
Mit den vorbereiteten Zahlen-Vektoren (als Eingaben) und den zugehörigen Stimmungswerten (als Zielwerte) passt das Netz schrittweise durch Backpropagation (Gradientenabstiegsverfahren) seine inneren Einstellungen (Gewichtungen) an. Dies geschieht in mehreren Durchgängen (Zyklen), sodass das Netz immer besser darin wird, die richtige Stimmung zu erkennen.
Auszug aus der Klasse SentimentNetzCSV:
double fehler = netz.trainiere(eingaben, ausgaben, lernrate, paketGroesse, wiederholungen);
System.out.println("Trainingsfehler: " + fehler);
Nach dem Training wird der Fehler zurückgegeben – also die Abweichung des Ergebnisses von den geforderten Zielwerten, und dieser Fehler wird ausgegeben.
6 - Test des KI-Systems
Nachdem das Netz trainiert ist, prüfen wir es mit neuen, separaten Testdaten, die es vorher nicht gesehen hat. So können wir feststellen, ob das Netz auch unbekannte Sätze richtig in die Stimmungen einteilen kann.
Tauchen Wörter aus den Testdaten nicht im Wörterbuch der Trainingsdaten auf, werden diese ignoriert.
Ebenso wird ermittelt, wie viele Testdaten korrekt eingeschätzt wurden.
Ein mögliches Ergebnis:
=== Ergebnisse zu den Testdaten ===
Text: Der Film gestern Abend war überwältigend gut.
Erwartet: positiv
Vorhersage: positiv
------------------------------
Text: Ich fand den Vortrag im Unterricht enttäuschend.
Erwartet: negativ
Vorhersage: negativ
------------------------------
Text: Das Mittagessen in der Schulkantine war durchschnittlich.
Erwartet: neutral
Vorhersage: positiv
------------------------------
Text: Die neue Schuluniform sieht modern und schick aus.
Erwartet: positiv
Vorhersage: positiv
------------------------------
Text: Der Biologieunterricht heute war ziemlich langweilig.
Erwartet: negativ
Vorhersage: negativ
------------------------------
Text: Die Schulbibliothek hat eine beeindruckende Sammlung.
Erwartet: positiv
Vorhersage: positiv
------------------------------
Text: Der Sportunterricht war anstrengend, aber spaßig.
Erwartet: neutral
Vorhersage: neutral
------------------------------
Text: Die Klassenarbeit in Mathe war überraschend leicht.
Erwartet: positiv
Vorhersage: negativ
------------------------------
Text: Die Pausen waren zu kurz und hektisch.
Erwartet: negativ
Vorhersage: negativ
------------------------------
Text: Der Geschichtsunterricht war informativ und spannend.
Erwartet: positiv
Vorhersage: positiv
------------------------------
Text: Die Lehrerin hat den Unterricht sehr langweilig gestaltet.
Erwartet: negativ
Vorhersage: positiv
------------------------------
Text: Das Schulfest war bunt und fröhlich.
Erwartet: positiv
Vorhersage: positiv
------------------------------
Text: Der Computerraum war voll von technischen Problemen.
Erwartet: negativ
Vorhersage: positiv
------------------------------
Text: Die Sporthalle wurde kürzlich renoviert und sieht toll aus.
Erwartet: positiv
Vorhersage: positiv
------------------------------
Text: Der Französischkurs war schwer verständlich.
Erwartet: negativ
Vorhersage: neutral
------------------------------
Text: Das Schulessen schmeckte überraschend gut.
Erwartet: positiv
Vorhersage: positiv
------------------------------
Text: Die Schulbusfahrt war ruhig und angenehm.
Erwartet: positiv
Vorhersage: positiv
------------------------------
Text: Die Bibliothek war überfüllt und laut.
Erwartet: negativ
Vorhersage: negativ
------------------------------
Text: Der Kunstunterricht inspirierte mich sehr.
Erwartet: positiv
Vorhersage: positiv
------------------------------
Text: Der Physikunterricht wirkte sehr trocken und öde.
Erwartet: negativ
Vorhersage: positiv
Absolut richtig erkannt: 14 von 20
Relativ richtig erkannt: 70.0%
7 - Qualität des KI-Systems bestimmen
Machen wir uns nun Gedanken um die Qualität des KI-Systems.
Over-/Underfitting
70% der Testdaten werden korrekt erkannt und 100% der Trainingsdaten. Tendenziell könnte dies ein Zeichen für Overfitting sein, da das Modell zu gut an die Trainingsdaten angepasst ist und damit zu eingeschränkt.
Spezifität und Präzision
Wir müssen zunächst festlegen, welche Klasse wir als „positiv“ (also als positive Klasse) betrachten. Dann gelten folgende Definitionen:
- Präzision (Precision): Von allen Sätzen, die als „positiv“ vorhergesagt wurden, wie viele waren tatsächlich positiv?
- Spezifität (Specificity): Von allen Sätzen, die eigentlich nicht positiv (also negativ oder neutral) sind, wie viele wurden korrekt als nicht positiv erkannt?
Schauen wir uns die Testdaten an und betrachten „positiv“ als die positive Klasse:
| Nr. | Erwartet | Vorhersage | Klassifikation bzgl. „positiv“ |
|---|---|---|---|
| 1 | positiv | positiv | TP |
| 2 | negativ | negativ | TN |
| 3 | neutral | positiv | FP (fälschlicherweise positiv) |
| 4 | positiv | positiv | TP |
| 5 | negativ | negativ | TN |
| 6 | positiv | positiv | TP |
| 7 | neutral | neutral | TN (da neutral ≠ positiv) |
| 8 | positiv | negativ | FN (positiv erwartet, aber nicht erkannt) |
| 9 | negativ | negativ | TN |
| 10 | positiv | positiv | TP |
| 11 | negativ | positiv | FP |
| 12 | positiv | positiv | TP |
| 13 | negativ | positiv | FP |
| 14 | positiv | positiv | TP |
| 15 | negativ | neutral | TN |
| 16 | positiv | positiv | TP |
| 17 | positiv | positiv | TP |
| 18 | negativ | negativ | TN |
| 19 | positiv | positiv | TP |
| 20 | negativ | positiv | FP |
Zählen wir nun:
- TP (True Positives): 9 (Nr. 1, 4, 6, 10, 12, 14, 16, 17, 19)
- FP (False Positives): 4 (Nr. 3, 11, 13, 20)
- FN (False Negatives): 1 (Nr. 8)
- TN (True Negatives): 6 (Nr. 2, 5, 7, 9, 15, 18)
Ergebnis:
- Präzision: ca. 69% (d.h. von allen als positiv klassifizierten Sätzen sind etwa 69% tatsächlich positiv).
- Spezifität: 60% (d.h. von allen Sätzen, die nicht positiv sind, erkennt das System 60% korrekt als nicht positiv).
Diese Werte helfen uns zu verstehen, wie zuverlässig unser Modell in Bezug auf die Erkennung der positiven Klasse ist. Die Werte sind noch nicht ganz zufriedenstellend.
Bias
Man sollte die Ergebnisse zu den Testdaten dahingehend überprüfen, ob diese bezogen auf ein Merkmal diskriminierend sind. Das scheint hier nicht der Fall zu sein.
Anpassung des KI-Systems
Es gibt verschiedene Möglichkeiten, das KI-System anzupassen:
- Netzwerk-Architektur verändern: Mehr/weniger Neuronen in der verdeckten Schicht, weitere verdeckte Schichten, …
- Lernrate anpassen.
- Anzahl der Trainingsdurchläufe anpassen.
- Mehr Trainingsdaten besorgen und darauf achten, dass diese möglichst unterschiedlich sind.
Mit dem folgenden Datensatz mit 160+40 Datensätzen, einer Architektur 10 > 3 und 3000 Wiederholungen werden bereits 87,5% der Daten korrekt erkannt. Dieses Ergebnis ist schon deutlich besser.
Dateien:
Achtung: Die Daten sind KI-generiert und nicht auf Korrektheit überprüft worden.
Java-Quelltexte
Hier können Sie die entsprechenden Java-Quellen herunterladen: